Introduction
The origin of this blog post is the recent debate spurred off Elon Musk and Mark Zuckerberg, on whether AI is good or bad for humanity.
Elon is an inspiration to many of us around the world, especially for anyone entrepreneurial, and also for us – the machine learning enthusiasts; self-driving cars, and his thoughts on AI and its applications in his companies (e.g., Tesla autonomous driving via its auto-pilot capabilities).
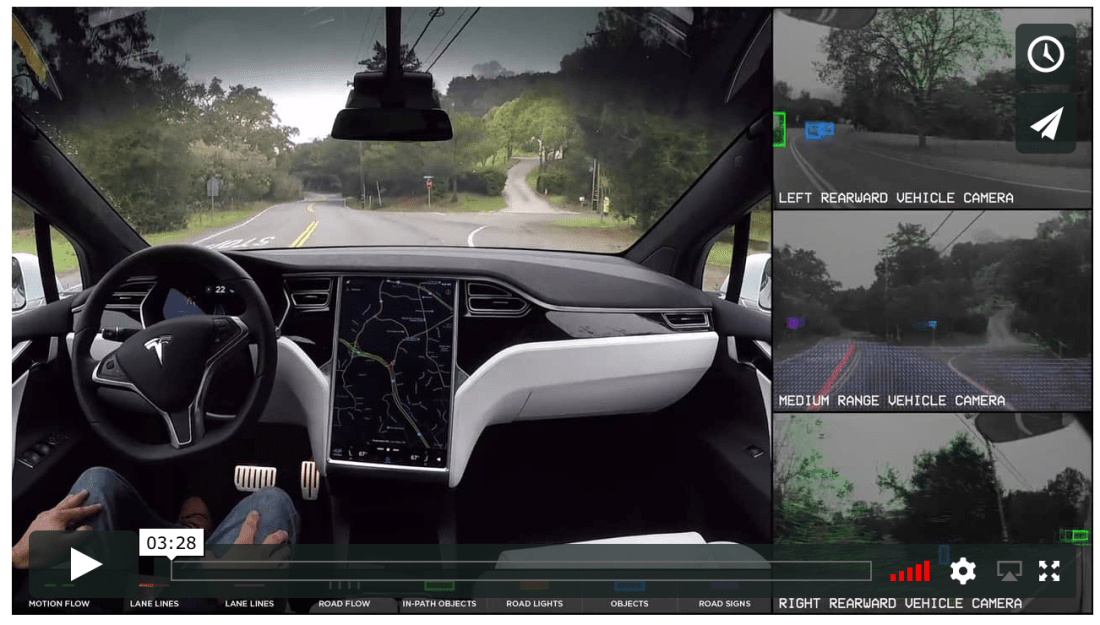
But sometimes, I tend to differ with his point-of-views on certain topics. For ex., We have to leave earth and go to Mars, to sustain humanity (Space X was founded primarily to make this possible sooner), and that robots with Super-intelligence, will take over the planet soon. Elon is a visionary, and like Stephen Hawking, he too believes that AI could one day supersede humans. He is right; or rather, he ‘could’ be right. But the point I would like to make in this blog post is that AI and deep learning in particular, is at a very nascent stage now, and considering the capabilities that we have built into AI systems so far, I am pretty sure that the doomsday type scenario that Elon points out, is definitely not in the near future.
As Andrew NG, the cofounder of Coursera and former chief scientist at Chinese technology powerhouse Baidu, recently pointed out in a Harvard Business Review event, the more immediate problem we need to address, is job displacement, due to automation, and this is an area that we must focus on, rather than being distracted by science fiction-ish, dystopian elements.
Limitations of Deep learning
At the recently held AI By The Bay conference, Francois Chollet, an AI Researcher at Google and inventor of the widely used deep learning library Keras, spoke about the limitations of deep learning. He said that deep learning is simply a more powerful pattern recognition system when compared to previous statistical and machine learning methods. “The most important problem for A.I today is abstraction and reasoning”, said Chollet.
Current supervised perception and reinforcement learning algorithms require lots of data, they’re terrible at planning, and are merely doing straightforward pattern recognition. However, by contrast, humans are able to learn from very few examples and can do very long-term planning. Also, we are capable of forming abstract models of a situation and manipulate these models to achieve “extreme generalization”.
Lets take an example of how difficult it is to teach simple humans behaviours to a deep learning algorithm. Lets examine the task of not being hit by a car as you attempt to cross a road. In case of supervised learning, we would need huge datasets of this (vehicular movement) situations with clearly labeled actions to take, such as “stop” or “move”. Then you’d need to train a neural network to learn the mapping between the situation and the appropriate response action. If we go with the reinforcement learning route, where we give an algorithm a goal and then let it independently determine the appropriate actions to take, the computer would need to die thousands of times before it learns to avoid vehicles in different situations. In summary, humans only need to be told once to avoid cars. We’re equipped with the ability to generalize from just a few examples and are capable of imagining (modeling) the dire consequences of being run-over by a vehicle. And so without ever (in most cases) losing our life or hurting us significantly, most of us quickly learn to avoid being run over by motor vehicles.
Talking of anthropomorphizing machine learning models, Francois Chollet in his recent blog post, has a very interesting observation:
“A fundamental feature of the human mind is our “theory of mind”, our tendency to project intentions, beliefs and knowledge on the things around us. Drawing a smiley face on a rock suddenly makes it “happy”—in our minds. Applied to deep learning, this means that when we are able to somewhat successfully train a model to generate captions to describe pictures, for instance, we are led to believe that the model “understands” the contents of the pictures, as well as the captions it generates. We then proceed to be very surprised when any slight departure from the sort of images present in the training data causes the model to start generating completely absurd captions.”
Another difference between how we, humans, interpret our surrounding, versus how these models do, is ‘extreme generalisation’ that we are good at, versus the ‘local generalisation’ that the machine learning models can do.
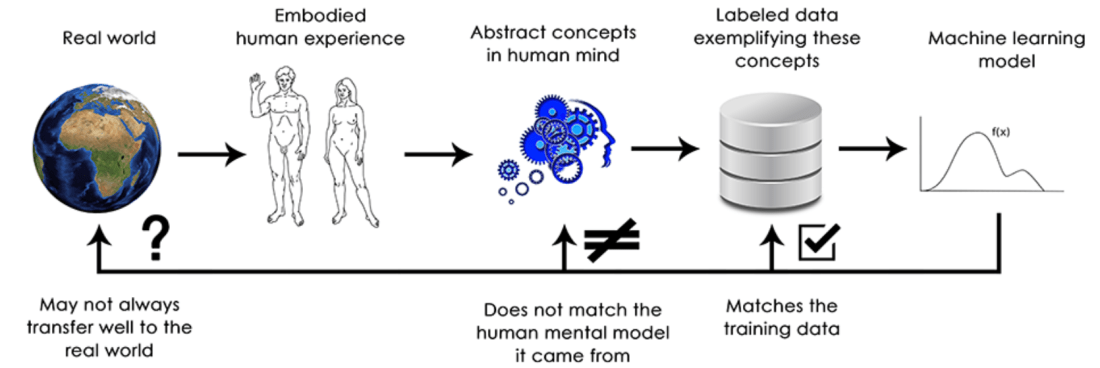
Lets take an example to understand this difference. If we take a young and smart 6 year old boy from Bangalore, and leave him in the town of Siem Reap in Cambodia, he will, in a few hours, manage to find out place to eat, and start communicating with the people around, and make his ends meet in a couple of days time. This ability to handle new situations, when we have never experience a similar one before – language, people, surroundings, etc., that is to perform abstraction and reasoning, far beyond what we have experienced so far, is arguably the defining characteristic of human cognition. In other words, this is “extreme generalization”; our ability to adapt to completely new, never experienced before situations, using very little data or even no new data at all. This is in sharp contrast with what deep/neural nets can do, which can be referred to as “local generalization”; that is, the mapping from inputs to outputs performed by deep nets quickly start to fall apart, if the new inputs differ even slightly from what they were trained with.
How Deep learning should evolve
A necessary transformational development that we can expect in the field of machine learning is a move away from models that merely perform pattern recognition and can only achieve local generalization, towards models capable of abstraction and reasoning, that can achieve extreme generalization. Whilst moving towards this goal, it will also be important for the models to require minimal intervention from human engineers. Today, most of the AI programs that are capable of basic reasoning, are all written by human programmers; for example the software that relies on search algorithms. All this will result in deep learning models which are not heavily dependant on supervised learning, which is the case today, and truly become self-supervised and independent.
As Francois calls out in his blog post, “we will move away from having on one hand “hard-coded algorithmic intelligence” (handcrafted software) and on the other hand “learned geometric intelligence” (deep learning). We will have instead a blend of formal algorithmic modules that provide reasoning and abstraction capabilities, and geometric modules that provide informal intuition and pattern recognition capabilities. The whole system would be learned with little or no human involvement.”
Will this result in machine learning engineers losing jobs? Not really; engineers will move higher up in the value chain. These engineers will then start focusing on crafting complex loss functions to meet business goals and use cases, and spend more time understanding how the models they have built impact the digital ecosystems in which they are deployed. For ex., interact and understand the users that consume the model’s predictions and the sources that generate the model’s training data. Only the largest companies can afford to have their data scientists spend time in these areas.
Another area of development could be, the models becoming more modular, like how the advent of OOP (Object-oriented programming) helped in software-development, and how the concept of ‘functions” help in re-using key functionalities in a software program. This will steer the way for the models becoming re-usable. What we do today, in the lines of model reuse across different tasks, is to leverage pre-trained weights for models that perform common functions, like visual feature extraction (for image recognition). When we reach this stage, we would not only leverage previously learned features (submodel weights or hyperparameters), but also model architectures and training procedures. And as models become more like programs, we would start reusing program subroutines, like the functions and classes found in our regular programming languages today.

Closing thoughts…
The result of these developments in the deep learning models, would be a system that attains the state of Artificial General Intelligence (AGI).
So, does all this, again take us to the debate i initially started with – a singularitarian robot apocalypse to takeover planet Earth? For now, and for the near-term future, I think its a pure fantasy, that originates from a profound misunderstanding of intelligence and technology.
This post began with Elon Musk’s comments; and I will end it with a recent comment from him – “AI will be the best of worst hing ever for humanity…”.
If you want to dwell deeper in this fantasy of Superintelligence, then do read Max Tegmark’s book Life 3.0 published last month. Elon himself, highly recommends it. :).

Another classic is Nick Bostrom’s Superintelligence – Paths, Dangers, Strategies. And, if you are a Python programmer, and want to start building Deep Learning models, then I strongly recommend Francois Chollet’s book Deep Learning with Python
Further reading
Here are some recent research papers highlighting limitations of Deep Learning:
- Deep Networks are Easily Fooled by Anh Nguyen at University of Wyoming
- Intriguing Properties of Neural Networks by Google’s Christian Szegedy and others.
- The Limitations of Deep Learning in Adversarial Settings, by Nicolas Papernot at Penn State University, and others.
Cover image source: https://regmedia.co.uk/