Artificial Intelligence (AI) and Machine Learning have become mainstream these days, but at the same time, they are some of the most used (abused) term/jargon in the last 2-3 years.
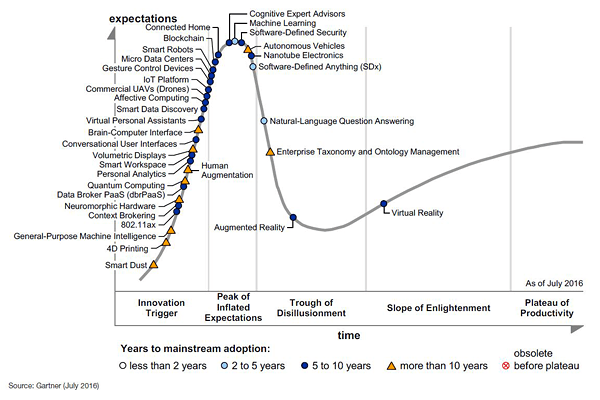
Last year’s Gartner hype cycle report (2016 Hype Cycle for Emerging Technologies – shown below) shows this trend clearly.
Why do we need AI in Cyber security
The biggest challenge in the Cybersecurity Threat Managment space today, is the ability (or lack of) of effective “detection” of cyber attacks. One of the key levers in making “detection” work is reducing the dependency on the “human” element in this entire threat management lifecycle:
- Let it be the detection techniques (signatures, patterns, and for that matter ML models and their hyper-parameters), or,
- The incident “response” techniques:
- involving human security analysts for analysing the detections, or,
- human security administrators to remediate/block the attacks at the network or system level
Introducing automation and bringing in cognitive methods in each of these areas, is the only way forward, to take the adversaries head-on. And there has been numerous articles, presentations and whitepapers published on why Machine Learning (ML) and AI will play a key role in addressing the cyber threat management challenge.
In my pursuit of understanding how AI can be used effectively in the cybersecurity space, I have come across products developed by some of the leading startups in this domain. And in this blog post, I attempt to share my thoughts on 10 of these products, chosen primarily on their market cap/revenue, IP (intellectual property) potential, and any reference materials available about their successful detections so far.
Note:
- I have tried to cover as much breadth I can, in terms of covering Products falling under various domains of Cybersecurity – Network detection, UEBA, Application security and Data security, and so there is a good chance I have missed some contenders in this area. AI in Cyber is a rapidly growing plateau, and I hope to cover more ground in the coming months.
- These Products are listed below in no particular order.
Lets get started.
1. PatternEx
Founded 2013, San Jose, California
https://www.patternex.com/
@patternex
PatternEx’s Threat Prediction Platform is designed to create “virtual security analysts” that mimic the intuition of human security analysts in real time and at scale. The platform reportedly detects ten times more threats with five times fewer false positives compared with approaches based on Machine Learning-Anomaly Detection technology. Using a new technology called “Active Contextual Modeling” or ACM, the product synthesizes analyst intuition into predictive models. These models, when deployed across global customers, can reportedly learn from each other and achieve a network effect in detecting attack patterns.
The process of Active Contextual Modeling (ACM) facilitates communication between the artificial intelligence platform and the human analyst. Raw data is ingested, transformed into behaviors, and run through algorithms to find rare events for an analyst for review. After investigation, an appropriate label is attached to each event by the analyst. The system learns from these labels and automatically improves detection efficacy. Data models created though this process are flexible and adaptive. Event accuracy is continuously improved. Historic data is retrospectively analyzed as new knowlege is added to the system.
Training the AI happens when the AI presents a set of alerts to human analysts, who review the alerts and define them as attacks or not. The analyst applies a label to the alert which trains a supervised learning model that automatically adapts and improves. This is a trained AI, and interesting concept, that attempts to simulate a security analyst, helping the AI system to improve the detection over a period of time.
PatternEx was founded by Kalyan Veeramachaneni, Uday Veeramachaneni, Vamsi Korrapati, and Costas Bassias.
PatternEx has received funding of about $7.8M so far.
2. Vectra Networks
Founded 2011, USA
http://www.vectranetworks.com/
@Vectra_Networks
Vectra Networks’ platform is designed to instantly identify cyber attacks while they are happening as well as what the attacker is doing. Vectra automatically prioritizes attacks that pose the greatest business risk, enabling organizations to quickly make decisions on where to focus their time and resources. The company says that platform uses next-generation compute architecture and combines data analytics and machine learning to detect attacks on every device, application and operating system. And to do this, the system uses the most reliable source of information – network traffic. Logs only provide low-fidelity summaries of events that have already been seen, not what has been missed. Likewise, endpoint security is easy to compromise during an active intrusion.
The Vectra Networks approach to threat detection blends human expertise with a broad set of data science and machine learning techniques. This model, known as Automated Threat Management, delivers a continuous cycle of threat intelligence and learning based on cutting-edge research, global learning models, and local learning models. With Vectra, all of these different perspectives combine to provide an ongoing, complete and integrated view that reveals complex multistage attacks as they unfold inside your network.
They have an interesting approach to use Supervised and Unsupervised ML models to detect cyber attacks. They have a “Global Learning” element, where supervised ML algorithms are used to build models to detect “generic” and “new known” attack patterns. “Local learning” element uses Unsupervised ML algorithms are used to collect knowledge of local norms in an enterprise, and then detecting deviations from those norms.
Vectra networks has received funding of about $87M so far, and has seen very good traction in the Enterprise Threat Detection space, where ML models are a lot more effective than using conventional signature/pattern based detections.
3. Darktrace
Founded 2013, UK
https://www.darktrace.com/
@Darktrace
Darktrace is inspired by the self-learning intelligence of the human immune system; it’s Enterprise Immune System technology iteratively learns a pattern of life for every network, device and individual user, correlating this information in order to spot subtle deviations that indicate in-progress threats. The system is powered by machine learning and mathematics developed at the University of Cambridge. Some of the world’s largest corporations rely on Darktrace’s self-learning appliance in sectors including energy and utilities, financial services, telecommunications, healthcare, manufacturing, retail and transportation.
DarkTrace has a set of products, which use ML and AI in detecting and blocking cyber attacks:
DarkTrace (Core) is the Enterprise Immune System’s flagship threat detection and defense capability, based on unsupervised machine learning and probabilistic mathematics. It works by analyzing raw network data, creating unique behavioral models for every user and device, and for the relationships between them.
The Threat Visualizer is Darktrace’s real-time, 3D threat notification interface. As well as displaying threat alerts, the Threat Visualizer provides a graphical overview of the day-to-day activity of your network(s), which is easy to use, and accessible for both security specialists and business executives.
Darktrace ICS retains all of the capabilities of Darktrace in the corporate environment, creating unique, behavioral understanding of the ‘self’ for each user and device within an Industrial Control systems’s network, and detecting threats that cannot be defined in advance by identifying even subtle shifts in expected behavior in the OT space.
Darktrace Antigena is capable of taking a range of measured, automated actions in the face of confirmed cyber-threats detected in real time by Darktrace. Because Darktrace understands the ‘pattern of life’ of users, devices, and networks, Darktrace Antigena is able to take action in a highly targeted manner, mitigating threats while avoiding over-reactions. It basically performs three steps, once a cyber attack is detected by the DarkTrace Core:
- Stop or slow down activity related to a specific threat
- Quarantine or semi-quarantine people, systems, or devices
- Mark specific pieces of content, such as email, for further investigation or tracking
DarkTrace has received funding of about $105M so far.
4. Status today
Founded 2015, UK
http://www.statustoday.com/
@statustodayhq
StatusToday was founded by Ankur Modi and Mircea Danila-Dumitrescu. It is a SaaS based AI-powered Insights Platform that understands human behavior in the workplace, helping organizations ensure security, productivity and communication.
Through patent-pending AI that understands human behavior, StatusToday maps out human threats and key behavior patterns internal to the company.
In a nutshell, this product collects all the user activity log data, from various IT systems, applications, servers and even everyday cloud services like google apps or dropbox. After collecting this metadata, the tool extracts as many functional parameters as possible and present them in easily understood reports graph. I think they use one of the Link analysis ML models to plot the relationship between all these user attributes.
The core solution provides direct integrations with Office 365, Exchange, CRMs, Company Servers and G-Suite (upcoming) to enable a seamless no-effort Technology Intelligence Center.
StatusToday has been identified as one of UK’s top 10 AI startups by Business Insider, TechWorld, VentureRadar and other forums, in the EU region.
Status Today has received funding of about $1.2M so far.
5. Jask
Founded 2015, USA
http://jask.io/
@jasklabs
Jask aims to use AI in solving the age old problem of tsunami of logs fed into SIEM tools which then generate events & alerts, and other indicators that security analysts face every day, which produce a never ending flood of unknowns which forces these analysts to spend their valuable time sorting through indicators in the endless hunt for real threats.
At the heart is their product Trident, which is a big data platform for real time and historical analysis over an unlimited amount of stored security telemetry data. Trident collects all this data directly from the network and complements that with the ability to fuse other data sources such as threat intelligence (through STIX and TAXII), providing context into real threats. Once Trident identifies a sequence that indicates an attack, it generates SmartAlerts, which analysts can use to have the full picture of an attack, also allowing them to spend their time on real analysis instead of an endless hunt for the attack story.
They have really interesting blog posts on their site, which are worth a read.
Jask has received funding of about $2M so far.
6. Fortscale
Founded 2012, Israel
https://fortscale.com/
@fortscale
Fortscale uses a machine learning system to detect abnormal account behavior indicative of credential compromise or abuse. The company was founded by security engineers from the Israeli Defense Force’s elite security unit. The products key ability is to rapidly detect and eliminate insider threats. From rogue employees to hackers with stolen credentials, Fortscale is designed to automatically and dynamically identify anomalous behaviors and prioritizes the highest-risk activities within any application, anywhere in the enterprise network.
Behavioral data is automatically ingested from SIEM tools and enriched with contextual data, and multi-dimensional baselines are created autonomously and statistical analysis reveals any deviations, which are then captured in SMART Alerts. All of this can viewed and analysed in Fortscale Console.
Fortscale was named Gartner Cool Vendor (2016) in the UEBA< Fraud Detection and User Authentication category.
More info about the product can be found here.
Fortscale has received funding of about $40 million so far.
7. Neokami
Founded 2014, Germany & USA
https://www.neokami.com/
@neokami_tech
Neokami attempts to tackle a very important problem we all face today – keeping a track of where all our and an enterprises’s sensitive information resides. Neokami’s CyberVault uses AI to discover, secure and govern Sensitive Data in the cloud, on premise, or across their physical assets. It can also scan images to detect sensitive information, as it uses highly optimized NLP for text analytics & Convolutional Neural Networks for image data analytics.
In a nutshell, Neokami uses a multi-layer decision pipeline, wherein it takes in data stream or files, and performs pattern matching, text analytics, image recognition, N-gram modelling and topic detection, using ML learning methods like Random Forest, to learn user-specific sensitivity over time. Post this analysis, a % sensitivity Score is generated and assigned to the data, which can then be picked up for further analysis and investigation.
Some key use cases Neokami tackles are – isolating PII to meet regulations such as GDPR, HIPPA, etc., discovering a company’s confidential information and intellectual property, scan images for sensitive information, protect information in Hadoop clusters, cloud, endpoints or mainframes.
Neokami was acquired by Relayr in Feb this year, and has received $1.1million funding so far, from three investors.
8. Cyberlytic
Founded 2013, UK
https://www.cyberlytic.com/
@CyberlyticUK
Cyberlytic call themselves the ‘Intelligent Web application security’ product. Their elevator pitch is they provide advanced web-application security using AI to classify attack data, identify threat characteristics and prioritize high-risk attacks.
The founders have had a stint with the UK Ministry of Defense, where this product was first used and has been in use support critical cybersecurity research projects in the department.
Cyberlytic analyzes web server traffic in real-time, and determines the sophistication, capability and effectiveness of each attack. This information is translated into a risk score, to prioritize incident response and prevent dangerous web attacks. And the underlying ML models adapt to new and evolving threats without requiring the creation or management of firewall rules. They key to their detection, is their patented ML classification approach, which appears to be more effective in detecting web application attacks than the conventional signature/pattern based detection.
Cyberlytic is a combination of two products – the Profiler, and the Defender. The Profiler provides real-time risk assessment of web-based attacks, by connecting to the web server and analyzing web traffic, to determine the capability, sophistication and effectiveness of each attack. And Defender, is deployed on web servers, and acts on the assessment performed by Profiler, by blocking and preventing web-based cyber-attacks from reaching critical web applications or the underlying data layer.
Cyberlytic has also been gaining a lot of attention in the UK and EU region; Real Business, an established publication in the UK, has named Cyberlytic as one of the UK’s 50 most disruptive tech companies in 2017.
Cyberlytic has received funding of about $1.24 million.
9. harvest.ai
Founded 2014, USA
http://www.harvest.ai/
@harvest_ai
Harvest.ai aims at detecting and stopping data breaches, by using AI-based algorithms to learn the business value of critical documents across an organization, and offer what it describes as an industry-first ability to detect and stop data breaches. In a nutshell, Harvest.ai is an AI powered advanced DLP system having the ability to perform UEBA.
Key features of their product MACIE, includes:
- Use AI to track intellectual property across an organization’s network, including emails and other content derived from IP.
- MACIE understands the business value of all data across a network and whether it makes sense for a user to be accessing certain documents, a key indicator of a targeted attack.
- MACIE can automatically identify risk to the business of data that is being exposed or shared outside the organization and remediate based on policies in near real-time. It not only classifies documents but can identify true IP matches to protect sensitive documents that exist for an organization, whether it be technology, brand marketing campaigns or the latest pharmaceutical drug.
- MACIE not only detects changes in a single users behavior, but it has the unique ability to detect minor shifts in groups of users, which can indicate an attack.
Their blog has some interesting analysis of some of the recent APT attacks, and how MACIE detected them. Definitely work a read.
Harvest.ai has received funding of about $2.71 million so far, and interestingly, they have been acquired by Amazon in Jan this year, for reportedly $20 million.
10. Deep Instinct
Founded 2014, Israel
http://www.deepinstinct.com/
@DeepInstinctSec
Deep Instinct focuses as End point as the pivot point, in detecting and blocking cyber attacks, and thus fall under the category of EDR. There is something going on in israel, for the last few years, as many cybersecurity startups (Cyberreason, Demisto, Intsights, etc.) are being founded by ex-IDF engineers in Israel, and a good portion of these startups are to do with Endpoint Detection and Response (EDR).
Deep Instinct uses deep learning to detect unknown malware in real-time, just by analysing the binary raw details of the binary picked up by the system. The software runs efficiently on the combination of central processing units (CPUs) and graphics processing units (GPUs) and Nvidia’s CUDA software for running non-graphics software on graphics chips. The GPUs enable the company to do in a day what would take three months for a CPU.
I couldn’t find enough documentation on their website to understand how this deep learning system actually works, but their website has a link to register for an online demo. So it must be definitely worth a try.
They are also gaining a lot of attention in the EDR space, and NVIDIA has selected Deep Instinct as one of the 5 most disruptive AI startups this year.
Deep Instinct has raised $50 million so far, from Blumberg Capital, UST Global, CNTP, and Cerracap.